Abstract
Transformer models have made great strides in generating symbolic music with local coherence. Yet, controlling the development of motifs in a structured way with global form remains an open research area. One of the reasons for this challenge is due to the note-by-note autoregressive generation of such models which lack the ability to correct themselves after deviations from the motif. In addition, their structural performance on datasets with shorter durations has not been studied in the literature. In this study, we propose Yin-Yang, a neuro-symbolic framework consisting of a phrase generator, phrase refiner and phrase selector models for development of motifs with long-term structure and controllability. The phrase refiner is trained on a novel corruption-refinement strategy which allows it to produce melodic and rhythmic variations of the original motif at generation time, thereby rectifying deviations of the phrase generator. We also introduce a new objective evaluation metric for quantifying how smoothly the motif manifests itself within the piece. Subjective evaluation results show our model achieves better performance compared to state of the art transformer models while having the advantage of being controllable and semi-interpretable, paving the path for musical analysis.
| Model | Audio | Description |
|---|---|---|
| Prompt | ||
| Compound Word Transformer | CP is able to follow the prompt for the first 30 seconds. After that, it diverges too much from the motif, generating excessive appogiatura like embellishments. | |
| Music Transformer | MT starts off with repetitive fragment like variations in the beginning but after 0:20, it repeats the same two notes till the end of the generation. | |
| Yin-Yang | YY is able to follow a melodic structure while adhering to the prompt. Its sections can be heard as follows: 0-0:22 - A section 0:23-0:34 - B section 0:35-0:53 - A section 0:54-1:07 - C section 1:07-end - A section |
|
| Yin-Yang Ablated | YYA is also able to follow a melodic structure but it could be argued that the phrases within the sections (not counting exact repetitions) are slightly less similar to that of YY. Its sections can be heard as follows: 0-0:21 - A section 0:22-0:35 - B section 0:36-0:53 - A section (lower octave) 0:54-1:05 - C section 1:06-end - A section |
| Model | Audio | Description |
|---|---|---|
| Prompt | ||
| Compound Word Transformer | CP losely follows the prompt up until the first minute but goes in a tangential direction after. Overlapping note durations can also be heard around 1:30 which is not desirable for the monophonic melodies. | |
| Music Transformer | MT initially generates a variation of the prompt which consists of a four note cadence (low-high-low-same). This cadence is repeated throughout in most of the generated phrases. Around 1:07-1:20 it is repeated excessively. | |
| YinYang | YY sections are arranged as follows: 0-0:26 A section 0:27-0:54 - B section 0:55-1:11 - A section (lower octave) 1:12-1:30 - C section 1:31-end - A section. The B section contains notes outside the key signature with the model's use of chromaticism. However, the phrases in the following sections revert back to the original key signature. |
|
| YinYang Ablated | YYA consists of distinct musical ideas. However, while the B section starts at 0:27, it becomes more prominent at 0:38, which is a variation of the new motif. At 1:03, the phrase is completed by notes of a higher pitch. While it comes as a surprise, it may be an unlikely occurrence if the phrase selector were added in like YY. Its sections are organized as follows: 0-0:26 - A section 0:27-0:57 B section 0:58-1:17 - A section 1:18-1:37 - C section 1:38-end - A section |
| Model | Audio | Description |
|---|---|---|
| Prompt | ||
| Compound Word Transformer | CP responds well to the motif in its first phrase. At the start of 0:18, the beginning of a new section can be heard. Around 0:41 there is yet another section that the model generates. However, throughout the piece, the music does not resemble the initial prompt. | |
| Music Transformer | MT generation comprises a structure of two phrases, of which one is varied while the other consisting of 4 notes (note-high-same-low) is repeated excessively throughout the piece. In addition, the generation does not refer back to the original prompt at all. | |
| YinYang | The first phrase generated by YY is a response to the prompt. The long note followed by the short one at the end of the motif are generated in the subsequent phrases, making it easy to relate to the prompt. The B section starts at 0:29 up with slightly different rhythmic patterns compared to section A. At 0:49, the original motif is restated with a call and response like variation. A new motif belonging to section C can be heard at 1:10. However, because the model looks at the last note of the previous phrase to produce a new motif for this section, it still retains the longer duration of the note in its cadence. At 1:33, the original theme from section A is stated again with a response that ends in an upward cadence. | |
| YinYang Ablated | YYA is full of variations. However, not all phrases within the sections are homogeneous, owing to the absence of the phrase selector. 0:22 marks section B. At 0:49, an unusual high pitched note can be heard which belongs to the same scale of the piece. Section A is restated at 0:58 in a higher octave. While the next phrase begins in a faster and interesting rhythmic pattern, the phrase generator repeats the Eb note a bit excessively. However, the model is able to break free from the repetition with the help of the refiner due to the start of the C section at 1:15. At 1:32, the A section theme is restated again with an interesting three-note rhythmic pattern that leads to the end of the piece. |
| Model | Audio | Description |
|---|---|---|
| Prompt | ||
| Compound Word Transformer | The last three notes of the initial motif can be heard in some moments with the CP model. However, the structure is vague with long duration notes in between and lacking distinct musical ideas. | |
| Music Transformer | MT repeats a fragment of the motif consisting of two notes (a short one and a long one right after) excessively throughout the piece, resulting in a monotonous rhythmic structure. | |
| YinYang | YY produces a melody with a diverse range of pitches, touching high as well as low note pitches. All sections have clear phrase boundaries with interesting variations. Section B starts at 0:20 but is kept short till 0:33 after which the original theme is stated in a lower octave. Section C starts at 1:01 with the new motif given by the different rhythmic structure. At 1:23 the A section theme is brought back at a lower octave. However, the cadence of the piece sounds incomplete. One reason for this may be due to the call and response like generation throughout the piece, setting up the perceptual expectation that there would be a response to the last phrase. However, as the number of phrases and sections are fixed before generation, the piece ends once the maximum phrases are obtained. Had the user specified an extra phrase for this section, it may have resulted in a phrase with a more satisfying cadence. | |
| YinYang Ablated | While YYA is able to adhere to the initial prompt in its structure while also producing diverse results, it does occasionally produce notes outside the scale of the piece due to the absence of the selector model. This is especially heard in the B section from 0:14 to 0:30. The A section theme comes back at 0:31 in a lower octave with variations of the motif produced till 0:47 when the C section starts. As the new motif is derived from an arbitrary phrase of the previous sections, it still retains some of the rhythmic patterns of the motif from section A, resulting in a similar three note fragment. The A section is stated again for the fifth section at 1:04. The last few notes leading up to the cadence in this section lie outside the scale, making it unexpected. This produces a musical tension just before resolving it with the cadence with notes of the same scale again. |
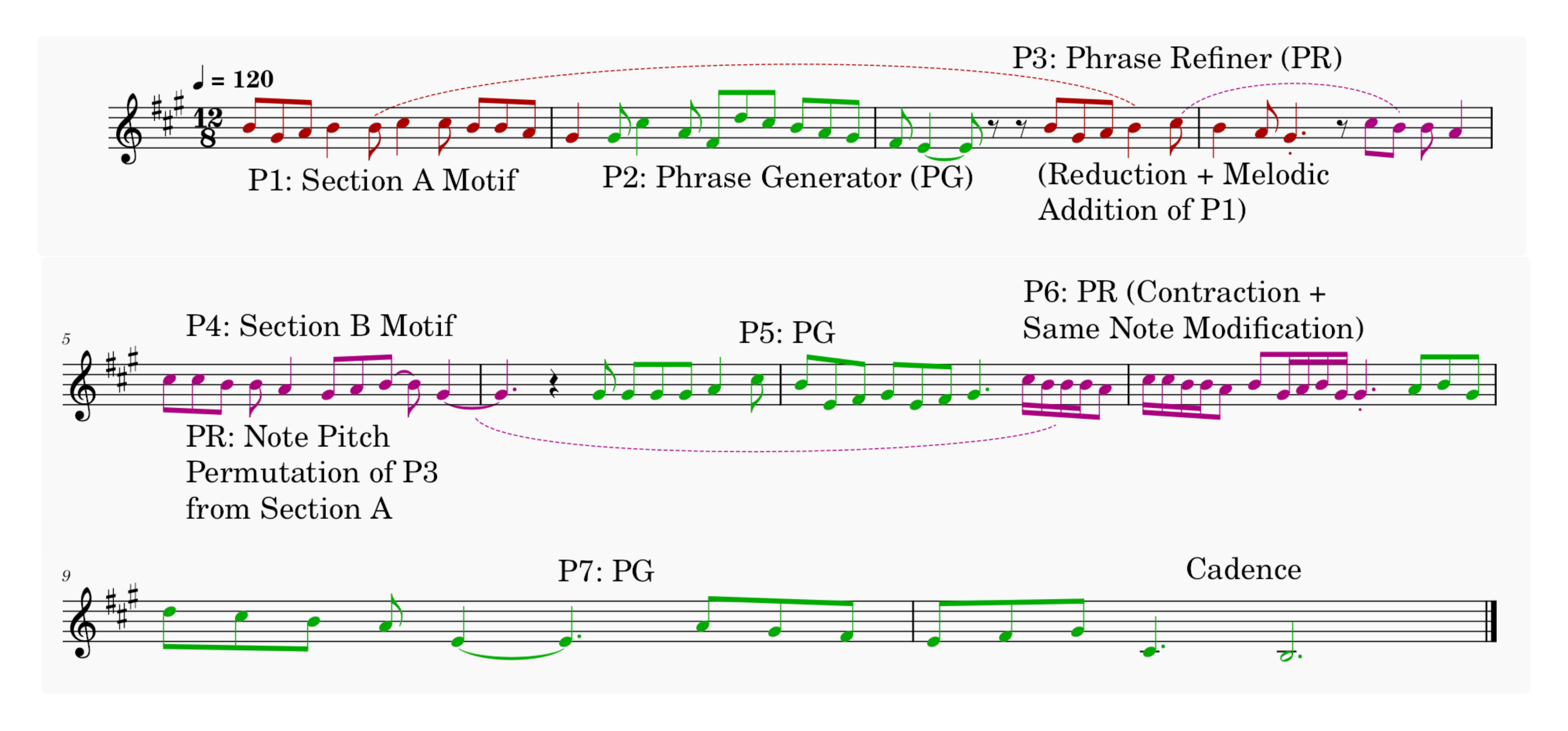
The score presented with the music demonstrates how the phrase generation and refinement model work simultaneously in the Yin-Yang generation framework. This example follows a AB structure consisting of 7 phrases in total (3 phrases for section A, 4 phrases for section B).
The motif is stated in P1. P2 is generated with the phrase generator. P3 uses the phrase refiner to transform and refine the motif using the reduction transformation paired with the melodic addition corruption. The refinement is with respect to phrase P2. The new section starts with P4 which arbitrarily chooses the P3 phrase and applies the note pitch and rhythm permutation transformation and corruption. P5 from the phrase generator elaborates on the new motif before the refiner is brought back to transform the section B motif using contraction (or diminution) transformation paired with same note modification corruption token. This phrase halves the duration of the motif to semi-quavers with respect to the previous phrase P5. Finally, P7 is generated as the last phrase in this example conditioned to generate a long duration for the cadence.
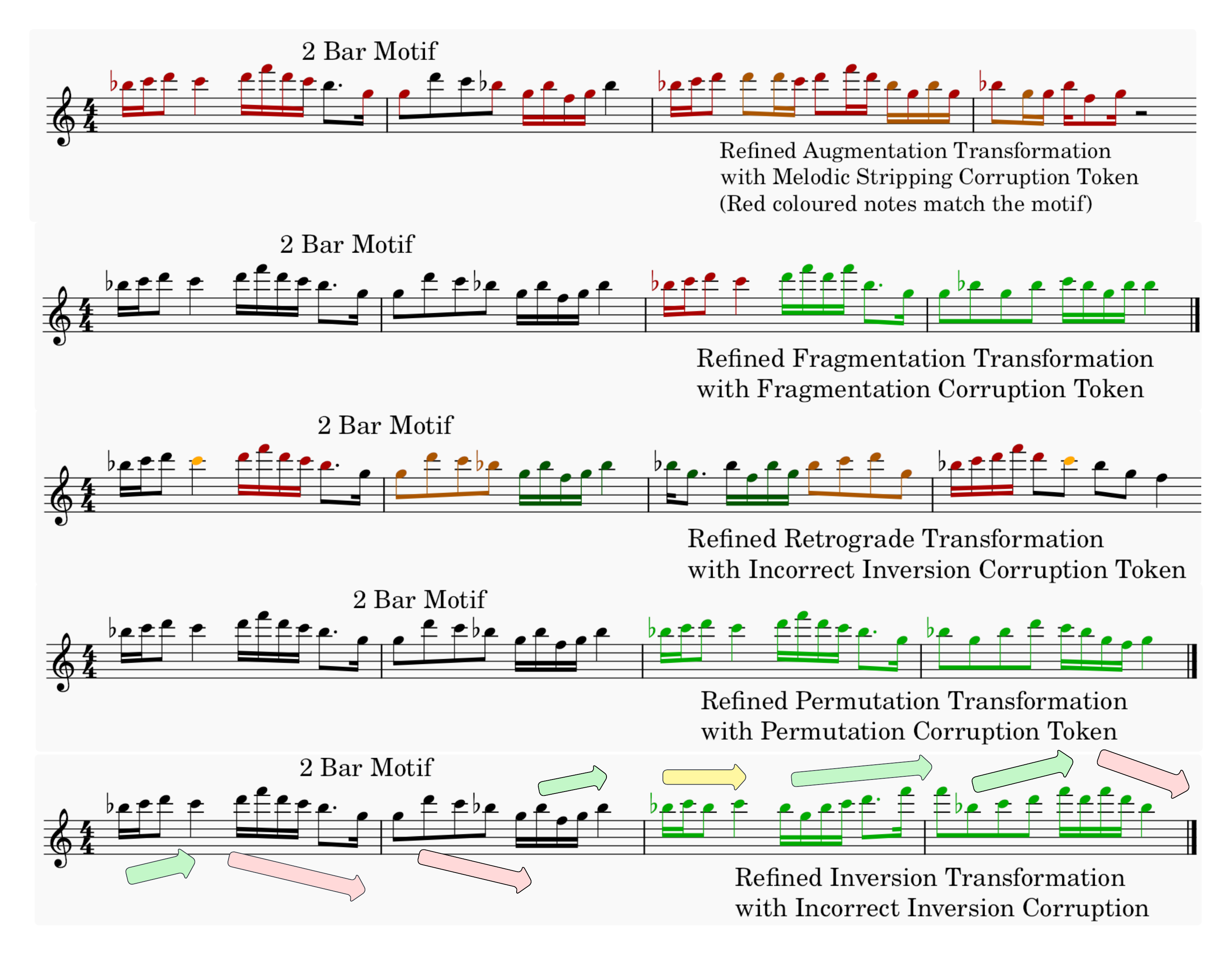
| Transformation | Corruption | Audio | Description |
|---|---|---|---|
| Augmentation | Melodic Stripping | Augmentation transformation increases the duration of the notes in the phrase. When combined with the melodic stripping corruption tokens, it tricks the refiner into filling in notes (with adjusted durations) between the augmented ones, as if they had been ommitted. This produces a high similarity variation. | |
| Fragmentation | Fragmentation | Fragmentation transformation and corruption together keep a fragment while generating the surrounding notes to produce a high similarity variation. | |
| Pitch Duration Retrograde | Incorrect Inversion | A retrograde on the pitch and duration of the transformed phrase paired with the incorrect inversion token generates a flexible retrograded phrase, taking the previous phrase into context. As heard, the pitch contour has now changed, yielding a low similarity variation. | |
| Pitch Duration Permutation | Pitch Duration Permutation | Pitch and duration permutation simply shuffles up the notes provided as conditioning to the refiner. While in practice it is intended to produce a low similarity variation, in this case as the previous phrase is also equivalent to the transformed one, it produces a highly similar variation. | |
| Modal Inversion | Incorrect Inversion | Modal inversion transformation inverts the intervals between the notes, causing the pitch contour to change, resulting in a low similarity variation. When paired with the incorrect inversion corruption token, the refiner takes the previous phrase (the 2 bar motif in this case) as musical context so as not to produce a strict melodic inversion but a more flexible musically meaningful one. |
The following videos compare the ground truth (first video) with the generated music by Yin-Yang (second video). The ground truth was intentionally excluded from tests to avoid biasing evaluations, as Yin-Yang aims to produce longer, more developmentally diverse melodies beyond the dataset's limitations, under the structural controls set by the user. Including the ground truth here allows listeners to contrast the original data with Yin-Yang's generative capabilities.
The following videos compare the ground truth with the ablated version of Yin-Yang without the phrase selector model.
We built an expressive harmonization model that takes in the generated melodies from the Yin-Yang framework and harmonizes them with controllable harmonic textures (down arpeggiated harmonic textures in this case). We also plan to extend this project by adding multiple instruments to harmonize the melodies.
Yin-Yang Generated Monophonic Melody:
Harmonized Melody (Down Arpeggiated Texture):