Northwestern University Deep Generative Models taught by Professor Bryan Pardo
What is this project about?
Automated species recognition through Artificial Intelligence (AI) can provide
ecologists and wildlife conservationists the means to detect and monitor
vocalizing avian species of interest. However, AI systems rely on a multitude
of data to learn the inductive biases and to generalize to the vocalizations of
bird species. This is problematic when classifying rare bird species which
have limited presence in naturally occurring audio data. In this project, we
try to address this problem by generating synthetic avian audio samples as
a type of augmentation that can be used in future works to improve the bird
sound classification accuracy.
Motivation and why this project is interesting
This problem is interesting because of two reasons:
Audio synthesis models have traditionally focused on synthesizing
human speech or on music generation. As such
there are limited models that have been put to the task of
generating environmental sounds or avian sounds. It would
be quite fascinating to see how these models perform at a
high entropy task such as this one.
Generating sounds that mimic avian calls is inherently difficult.
For example, there are often background environment
related noises coming from insects, wind/rain, humans, vehicles, etc.
Second, bird calls are quite varied and even the
same bird species could make a different sound, depending
on the motive and context. Third, the range of avian calls
across species is also quite large as opposed to human speech.
Finally, bird call datasets often consist of weak labels, where
annotators do not know the precise location of avian calls in
the audio files against silence as compared to text transcriptions in speech datasets.
Thus, there exists ample of challenges and opportunities to address
and take research on synthesizing avian calls to the next level.
Thus, there exists ample of challenges and opportunities to address
and take research on synthesizing avian calls to the next level.
Intellectual Interest And Practical Utilities
Every year, there are many species of birds that are put on the
endangered or extinct list. Automated bio-acoustics through the use
of AI provides a more efficient way for humans to measure conservation
efforts to protect wildlife. Thus, by improving the means
to identify bird species as an overarching goal, we are working
towards enhancing environmental conservation and protection of
biodiversity. This project is highly cross-functional and its outcome
could potentially open research avenues to other wildlife species of
interest.
Dataset Description
We use a subset of the xccoverbl dataset in our experiments. This dataset is available on
Kaggle.
It contains vocalizations of 88 bird species commonly observed in the UK,
gathered from the large Xeno Canto collection. There are 263 audio files in the dataset
with a sampling rate is 44.1kHz. Of these 263 audio files, we manually selected 153 files
containing birds whose vocalizations were distinct and whose audio clips do not suffer
from long periods of silence gaps in between the calls.
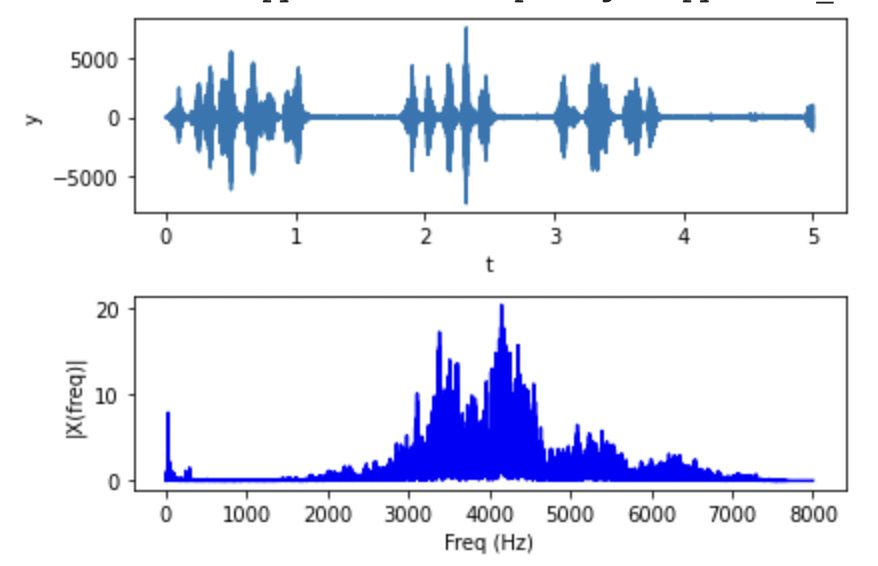
High-Pitched Sounds and Silence Gaps
Here is a pictorial representation of the high-pitched avian sounds (around 4000 Hz) coupled with silence gaps between vocalizations.
Human speech is around 100Hz and piano sounds are around 2000 Hz and these datasets do not contain silence gaps or environmental
noise like bird sound datasets do. This is makes bird sound synthesis an extremely challenging task!
How did we choose the final training samples?
We manually went through 3-4 random audio clips for all the species folders and rated them on
a scale of 1-5 on the following attributes:
Silence gaps between calls: Less = better
Vocalization of background species: We decided to retain audio clips where background
species had sounds as opposed to complete silence
Sharpness and clarity of foreground calls
Number of training samples per folder for each species: More = better
We chose 2,336 audio samples out of the lot by filtering the ratings which were 4.5 or above. These were used towards
training (88%), validation (6%) and test (6%).
Model Choice
There exist many potential ways to synthesize sounds (autoregressive, GAN, diffusion, flow based).
However, we decided to go with autoregressive methods as we thought these may be suitable to yield good quality generated audio.
This is because autoregressive models can tractably compute exact likelihoods of unbounded length,
making them appropriate for high entropy distribution problems such as bird sound synthesis. Before arriving to this conclusion,
also experimented with a variety of models types such as WaveGAN, DiffWave, parallel WaveGAN (vocoder) and SaShiMi. In our experiments,
we found parallel WaveGAN vocoder to recreate high-fidelity audio from a spectrogram representation. However, this was not an end-to-end
generation framework and we would need to train a spectrogram generator separately for this task. So our next best choice was to go with
SaShiMi, an autoregressive state-of-the-art state space model for unconditional generation.
State space models
The State Space Model (SSM) is mainly based on the Control Engineering concept
(https://srush.github.io/annotated-s4/#part-1-state-space-models).
The authors proposed a non-transformer version to predict very long sequences.
In Control Engineering, usually, 3 parameters are learned, whereas the authors of the SSM paper omitted one because
that is essentially a skip connection. So, three matrices (weights) are needed to be learned for the SSM mapping.
After that, the authors proposed a way to discretize the continuous representation using Bilinear Modeling. Based on that,
they first built a Recurrent Network intuition for the signal prediction.
Then, they proposed Discrete Convolution based on the unrolled SSM information and passed it through their special
filter for prediction. Both the Convolution and Recurrent generation procedures worked well. Using a combination of these
two, they build the S4 blocks.
However, the process comes with two big issues. First, memorizing the long sequence.
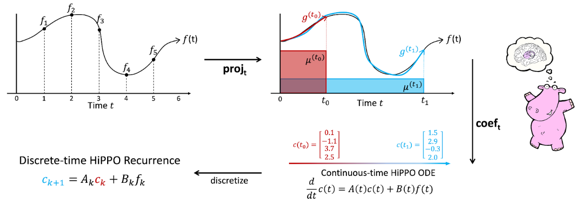
For Transformers, it was very easy. Here, the authors utilized HiPPO (a previously proposed method by one of the authors)
to memorize a 1-D function over a long time. HiPPO matrix computation is straightforward as it tracks the coefficients of
Legendre Polynomial (approx. prev. hist) and updates them across time. HiPPO matrix-based discretized outputs are then
used for the final SSM. Here is a picture that illustrates the process:
Figure: HiPPO matrix learns to approximate continuous function ‘f’ by adapting the coefficients.
Image source: https://srush.github.io/annotated-s4
The second issue is memory overhead. Usually, S4 blocks are stacked, but they come with high memory requirements.
The authors found an interesting property in the Transition Matrix (one of the three metrics discussed earlier).
They are Diagonal Plus Low-Rank (DPLR). The authors utilized the DPLR property of the Transition and HiPPO matrix
(which was Normal Plus Low-Rank, but converted to DPLR property) and then made the whole calculation process efficient.
In summary, an S4 block is DPLR SSM + DPLR HiPPO and can easily handle long-range sequences as they can be stacked
multiple times without any memory/computation overhead.
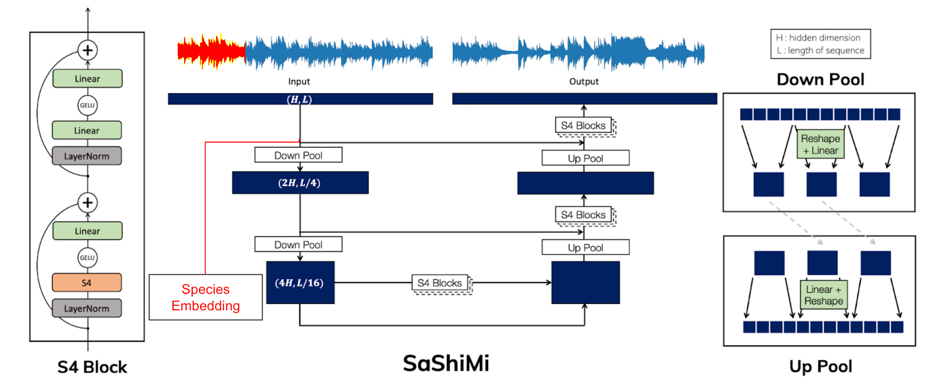
SaShiMi Model Architecture + Our Enhancements
Karan Goel, Albert Gu, Chris Donahue, Christopher Re Proceedings of the 39th International Conference on Machine Learning, PMLR 162:7616-7633, 2022.
As seen in the image above, the SaShiMi architecture consists of
multiple tiers, with each tier composed of a stack of residual S4 blocks. The top tier processes the raw audio
waveform at its original sampling rate, while lower tiers process downsampled versions of the input signal.
The output of lower tiers is upsampled and combined with the input to the tier above it in order to provide a
stronger conditioning signal. Our enhancements to this architecture is adding a species class conditioning block to the
64-dimensional hidden representations of each timestep of the input signal right before it gets fed into the downsampled block.
Here, in the conditioning block, we have an embedding matrix for the species code followed which is added to the hidden
representation of the audio input and then passed through feed-forward layers with a SiLU activation function.
Adding in this species conditioning improved our validation loss slightly. However, there may be better ways to
implement the class conditioning at strategic locations throughout the network to ensure that it actively maximizes
the influence on the generated timestep.
Experiments
We trained the model for 150 epochs on 2,155 five second audio clips at a 16 kHz sampling rate. The training time
took ~24 hours using 3 GPUs.
Generated Audio Samples
Unconditional Generation (no prompt)
Conditional Generation (1 sec prompt)
Conditional Generation (3 sec prompt)
Real Audio Samples
Discussion
While the SaShiMi model is able to learn the amplitude envelope of the avian vocalizations, it has trouble learning the
frequencies. As a result, the generated sounds sound noisy. There are some examples in which the model generates
whistling like sounds towards the end. In addition, towards the very end of the conditionally generated audio clip using
the 3-second prompt (last row), the generated sounds seem to be birds chirping in the background. Although these sounds are
faint and scattered all over, it is still promising!
We have a few theories as to why the model is not able to learn the frequencies well enough, resulting in generated sounds
being noisy:
High entropy problem: While this dataset was the cleanest we could find online, bird sound synthesis
is a high entropy problem in general. There are overlapping calls from multiple species in the background.
The high biodiversity in the environment makes this a very high entropy task.
Low energy frequency bins: Extending on the noise levels from the previous point, the background
sounds from the environment result in low energies across various frequencies as can be visually inspected
via a spectrogram. This translates to learning irrelevant frequencies for the model, resulting in noisy outputs.
Silence gaps: While we cherry-picked the training samples which had the least amount of silence between
foreground calls, there were still some audio clips that had a 2-3 second silence. This could have adversely impacted
the model.
Training time and # of training samples: The authors of SaShiMi trained their model on the YouTube dataset
for 1 whole week. In comparison, we only trained ours for 1 day. It's possible that the training time
or number of training audio clips (~3 hours) were insufficient.
Further Improvements / Future Work
Better preprocessing to remove silence between calls could definitely add value to improving this model further.
Adding in a bird sound enhancer / environment sound denoiser to the preprocessing pipeline
such as my previous work
can help reduce the unnecessary frequencies to be learned by the model.
End-to-end audio spectrogram generation and neural vocoding techniques may also be worth exploring.